Charlton Smith
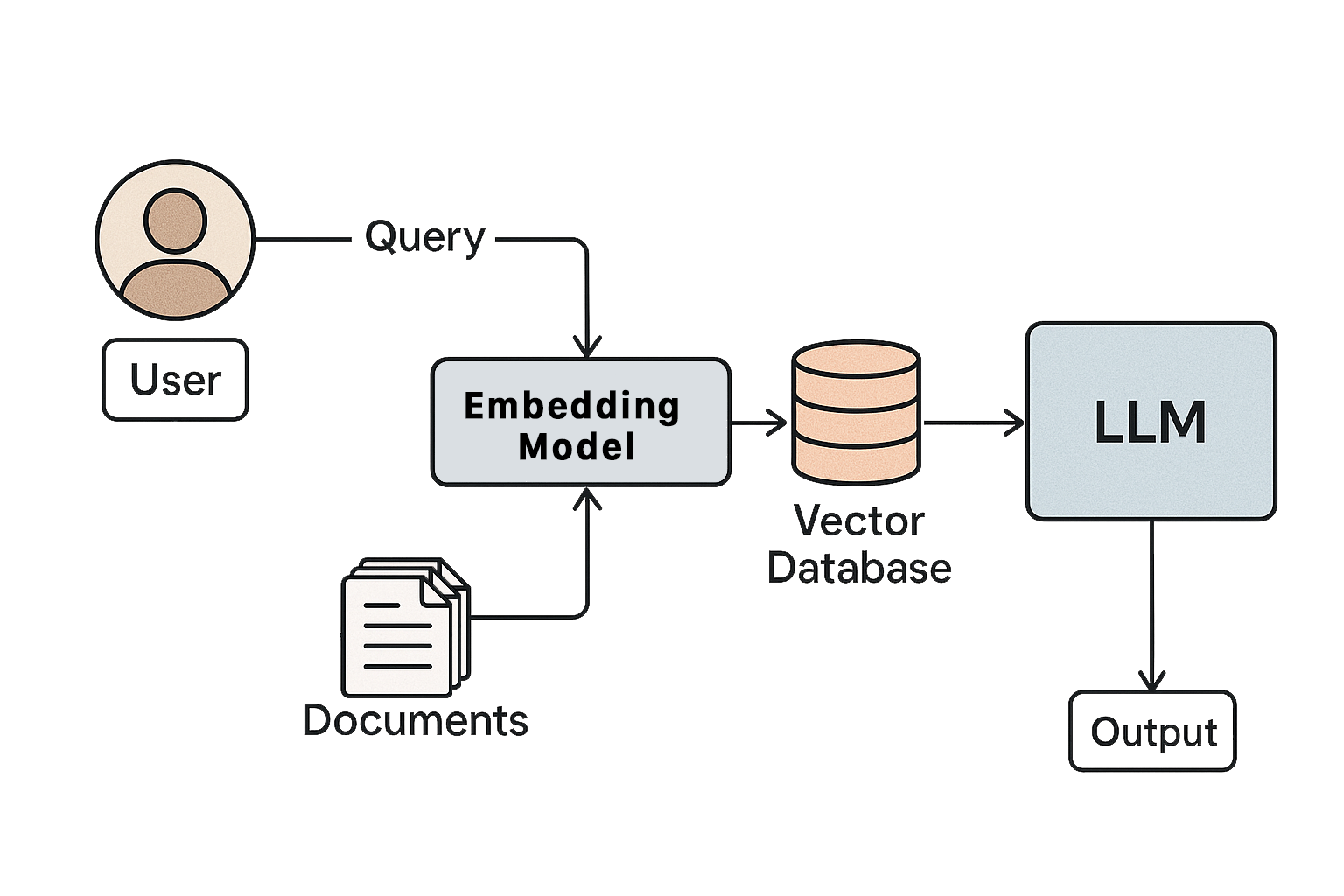
The bedrock of modern information systems has long been traditional databases, serving as an organized repository for storing and retrieving data to support a multitude of applications and decision making processes. Traditionally, these databases, particularly relational databases, have relied on structured schemas and query languages to manage and access information. However, advances in artificial intelligence have enabled large language models (LLMs) and related neural architectures to serve a role analogous to databases. These models can store vast amounts of knowledge (learned from data) and allow users to query that knowledge in natural language. In a sense, an LLM can be pictured as a database that supports open-ended semantic queries; a longstanding ambition in data management. Instead of defining schemas and creating the structure query to search for information, we can use a vector database and a Deep Learning model to synthesize information stored within their model. I will explore how AI models use context to retrieve specific facts, and even synthesize information similar to how databases join or aggregate data. In this paper we will also examine mechanisms like retrieval-augmented generation (RAG), the use of vector databases (e.g. pgvector) for neural retrieval and the role of embeddings where AI systems complement traditional databases, along with their advantages and limitations.
LLMs are trained on massive amounts of text, and during training stage they encode factual and linguistic knowledge in their weights. In effect, the model’s parameters act as a compressed store of information from the training data. For example, GPT style models can recall historical facts, definitions, or programming knowledge that was present in their training text. This is why models like Gemini, ChatGPT, Sesame AI can often answer trivia questions such like a read only database with a world of knowledge. Research has even likened the idea of pre-training language models to knowledge bases, noting they require no schema and can be queried on an open class of topics however this knowledge is distributed across of billions of parameters, so it isn’t organized in discrete records or tables. Accessing it relies on prompting the model in just the right way to recall relevant information.
Let’s look at Google’s Attention is all you need to understand vector embeddings. The Transformer model architecture is split into 2 distinct parts that consist of the encoder and decoder architecture and these components work in conjunction with one another. Here’s a simplified view of the Transformer architecture. (Figure 1)
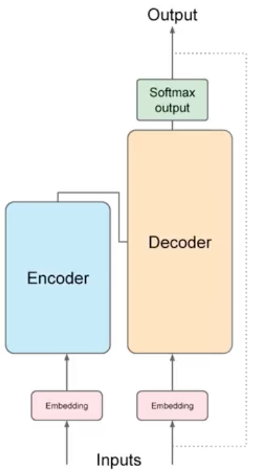
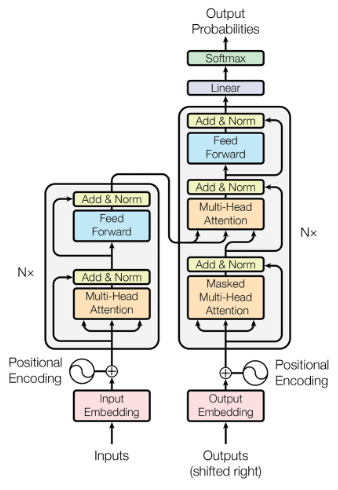
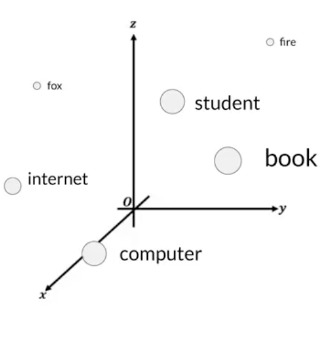
The encoder architecture (Figure 1) is responsible for taking in text not as alphanumeric text but represented as tokenized digits, with each word representing an index in say a dictionary of all possible words the model can work with. Creating the input text as vectors of tokenized numerical indexes we can then pass that information to the embedding layer of the architecture model. This layer is a trainable vector embedding space, a high dimensional space where each token is represented as a vector and occupies a unique location within that space. Each tokenized id in the vocabulary is matched to a multidimensional vector, and the intuition is that these vectors learn to encode the meaning and context of individual tokens in the input sequence. With the embedding layer you could plot the words into a multidimensional (see. figure 3) space and see the relationships between those words.
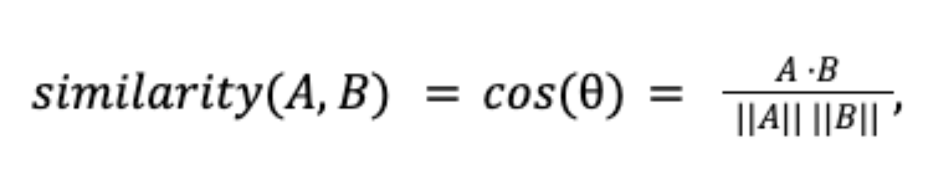
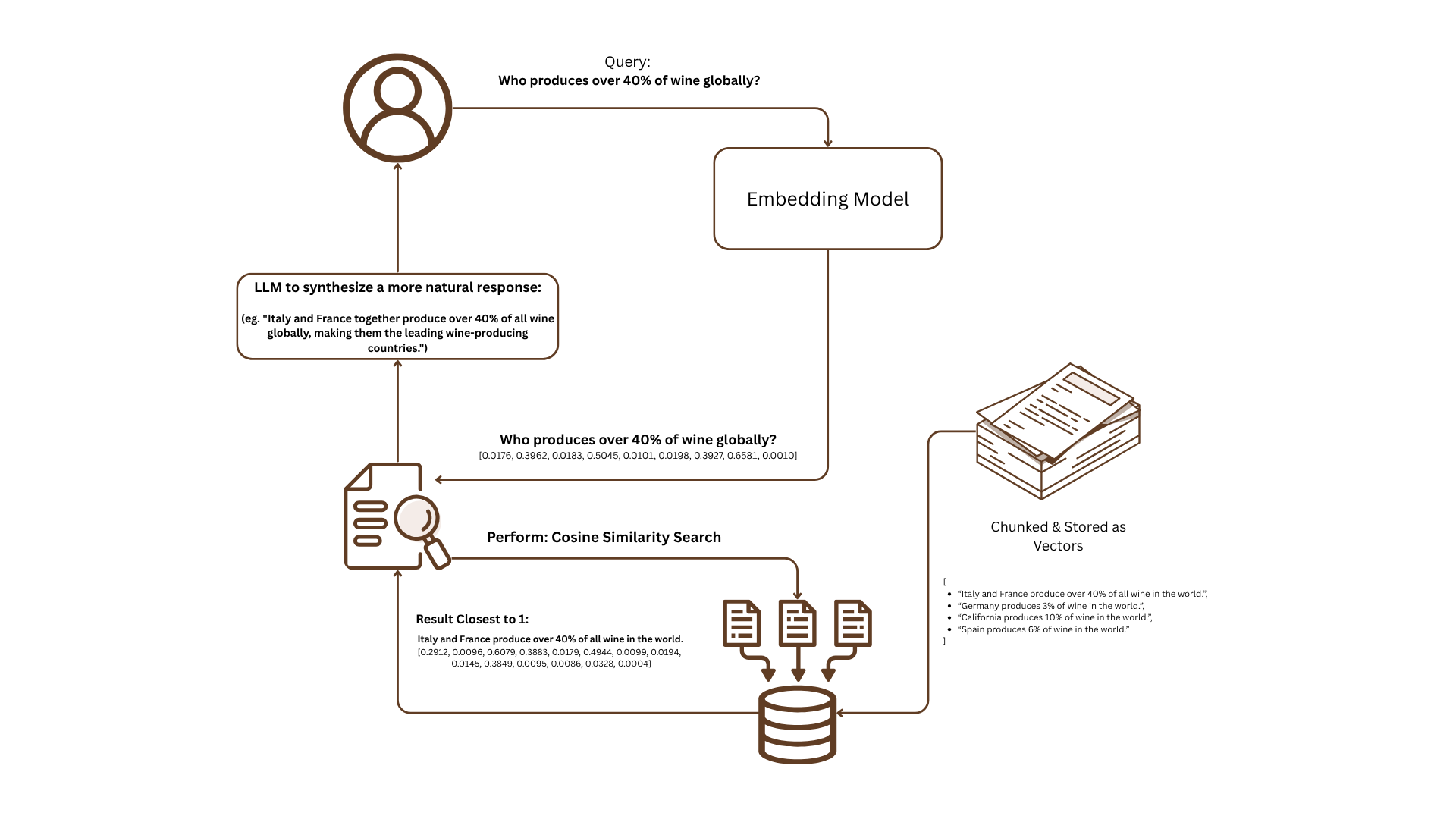
Our initial and critical step in leveraging vector search is data preparation, which lays the groundwork for an effective semantic retrieval. This step involves a two-fold process. First, segmenting the source document into smaller, manageable units or "chunks", which can be textual or data based. The quality of text that you decide to chunk is a crucial design decision. Smaller chunks might capture more localized semantic nuances but could lose broader context. Larger chunks retain more context but might dilute specific information. For textual data, suitable chunk sizes could range from individual sentences to entire paragraphs, or even sections, depending on the nature of the document and the anticipated query types. For structured data, a "chunk" might represent a single record or a grouping of related data points. The key objective is to create chunks that are semantically coherent and relevant on their own while still maintaining a clear lineage back to the original source document. This traceability is essential for providing context and verifying the retrieved information. To illustrate, a three page paper discussing different aspects of a research topic could be divided into around 30 individual text segments (e.g., paragraphs or sentences), each focusing on a specific subtopic and ensuring that each segment can be uniquely identified as originating from that particular paper. Second, after the document is chunked, the next step is applying embedded tokenization to these chunks to generate vector embeddings. This process involves using a pre-trained or custom trained embedding model. These models are designed to map words, phrases, or entire chunks of text into a high-dimensional vector space (Not all embedded models are created equally so it is important to always use the same tokenizer). The underlying principle is that semantically similar pieces of text will be located closer to each other in this vector space. The dimensions of these vectors (often ranging from a few hundred to thousands) capture various aspects of the meaning and context of the input text. Different embedding models, such as Word2Vec, GloVe, Sentence-BERT, or OpenAI's embeddings, employ different architectures and are trained on vast amounts of text data to learn these semantic relationships. The choice of embedding model significantly impacts the quality of the vector representations and, consequently, the effectiveness of the vector search. The output of this step is a numerical vector for each chunk, representing its semantic essence.
Once the data is vectorized and stored in our database, the process of querying begins. When a user poses a question or provides a search term, this query is also transformed into a query vector using the same embedding model that was used to vectorize the document chunks. Consistency in the embedding process is important to ensure that the query vector and the document vectors reside in the same semantic space, allowing for meaningful comparisons. This query vector is then used to search the vector database for the most similar stored vectors using cosine similarity. pgvector, as a PostgreSQL extension, provides this capability within a relational database framework, offering functionalities like indexing (e.g., using Approximate Nearest Neighbors - ANN algorithms) to speed up the search process. Cosine similarity is a common metric used to measure the angle between two vectors, providing a value between -1 and 1. A cosine similarity of 1 indicates that the vectors are pointing in the exact same direction (high semantic similarity), while a value of -1 indicates opposite directions (low similarity), and 0 indicates orthogonality (no direct semantic relationship). The vector database calculates the cosine similarity between the query vector and all the stored document vectors and returns the vectors with the highest similarity scores with the most similar vector pointing back to a specific text chunk, which can be decoded into a human-readable answer. Each vector stored in the database is associated with its original text chunk or data record so the corresponding content can be retrieved and presented to the user as the search result. This direct retrieval provides a basic form of answer to the user's query, based on semantic relevance.

In its early stages, Retrieval-Augmented Generation (RAG) operated on a fundamental process involving three steps: organizing information (indexing), finding relevant pieces (retrieval), and generating an answer. This initial framework as we just detailed is what we called a Simple RAG approach or sometimes referred as Naive RAG. However, as the complexity of tasks and application demands grew, the shortcomings of this basic RAG approach became increasingly evident. The primary limitation lies in its heavy reliance on the surface-level similarity between a user's question and the stored information. This simple matching can lead to poor performance when dealing with intricate queries or when the information chunks themselves vary significantly. The main challenges associated with this Naive RAG approach is the limited understanding of the user's questions. The semantic similarity between a query and a document snippet doesn't always reflect a true understanding of the user's intent and relying solely on similarity calculations for retrieval doesn't delve into the deeper relationship between the question and the available information. Directly feeding all retrieved chunks into the language model isn't always beneficial because an excess of repetitive or noisy information can hinder the language model's ability to identify crucial details because this can increase the likelihood of the model to hallucinate an inaccurate or fabricated response.
Unlike traditional databases that excel at structured data and exact matches, vector databases shine when the objective is to find semantically related content. This comes from their ability to index, and search based on the meaning of data, effectively accessing a rich "knowledge set" of information encoded in vector embeddings. Performing semantic searches or similarity-based queries using standard SQL constructs becomes computationally expensive and often incorrectly returns results, as they lack an inherent understanding of the underlying meaning of the data. However, it's important to note that traditional databases still hold significant value and can be employed alongside vector databases. They can be particularly useful for providing well-defined, structured context that complements the semantically similar results retrieved from the vector database, offering a more comprehensive understanding for the user's query. Imagine a scenario where a user asks a question about a specific product. The vector database can quickly retrieve a set of semantically similar product descriptions. To provide a comprehensive answer, one might then leverage a traditional database to fetch structured information about those products, such as their price, availability, customer reviews, or technical specifications. This structured data, retrieved based on identifiers linked to the vector embeddings, provides the well-defined context that complements the semantic similarity.
In conclusion, the landscape of data management and information retrieval is being significantly reshaped by the emergence and increasing sophistication of vector databases. While traditional relational databases remain indispensable for their robust handling of structured data and precise transactional operations, vector databases offer a powerful paradigm for navigating the complexities of semantic similarity and knowledge representation. Their ability to index and query based on the meaning of data, through dense vector embeddings, unlocks new possibilities for content discovery, recommendation systems, and intelligent search applications that go beyond simple keyword matching. Furthermore, the advent of LLMs introduces another transformative layer to this ecosystem. By leveraging the semantic understanding provided by vector databases, the reasoning and generative capabilities of LLMs, we can move beyond simple retrieval towards sophisticated question answering, summarization, and the generation of contextually rich and human-like responses. Prompt engineering becomes a crucial skill in orchestrating this interplay, guiding LLMs to effectively utilize the semantically relevant information retrieved from vector databases. Ultimately, the future of intelligent information systems likely involves a hybrid architecture where the strengths of traditional databases, vector databases, and LLMs are strategically combined. This integrated approach promises to deliver more intuitive, context-aware, and powerful solutions for accessing and understanding the vast amounts of data available today and in the future.
Source code example:
Charlton Smith. 2025. Similarity Search with Transformers + RAG. (May 2025). https://github.com/Mr-Smithy-x/NaiveRag/blob/main/similarity_search_with_rag.ipynb
Sources:
Francois Chollet. 2022. 11.4 The Transformer Architecture. In Deep learning with python Francois Chollet. Shelter Island: Manning Publications, 336–339.
Xuan-Son Nguyen. 2024. Code A simple rag from scratch. (October 2024). Retrieved May 15, 2025 from https://huggingface.co/blog/ngxson/make-your-own-rag
Rajeev Sharma. 2025. Exploring advanced rag techniques for ai. (2025). Retrieved May 15, 2025 from https://markovate.com/blog/advanced-rag-techniques/
Fabio Petroni Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel et al. 2019. Language models as knowledge bases? (September 2019). Retrieved May 15, 2025 from https://arxiv.org/abs/1909.01066
Simon J.D. Prince. 2023. 12. Transformers. In Understanding deep learning. Cambridge, MA: The MIT Press, 216–219.
Victor Morgante. 2024. A new class of database: Small data on large language models. (June 2024). Retrieved May 15, 2025 from https://generativeai.pub/a-new-class-of-database-small-data-on-large-language-models-526b2bce6b99
Hopworks. What is retrieval augmented generation (RAG) for LLMS? Retrieved May 15, 2025 from https://www.hopsworks.ai/dictionary/retrieval-augmented-generation-llm.
Roie Schwaber-Cohen. 2023. What is a vector database & how does it work? use cases + examples. (May 2023). Retrieved May 15, 2025 from https://www.pinecone.io/learn/vector-database/
Dave Bergmann and Cole Stryker. 2025. What is vector embedding? (April 2025). Retrieved May 15, 2025 from https://www.ibm.com/think/topics/vector-embedding
Website: https://usa.charltonsmith.nyc/
Android App: https://appdistribution.firebase.dev/i/34b4208544e058cb